我们知道在循环体中去改变一个 list,是不安全的作法,可能导致错误的结果。例如写一个函数,接受两个参数a和b,功能是在列表a中删除所有b中出现的元素。
以下这种写法就不正确:
def remove_el(org, dest):
for i, v in enumerate(org):
if v in dest:
org.pop(i)
输入 a = [1, 3, 3, 4, 4, 5], b = [3, 4], 结果a变成了 [1, 3, 4, 5],而不是预期的 [1, 5]。
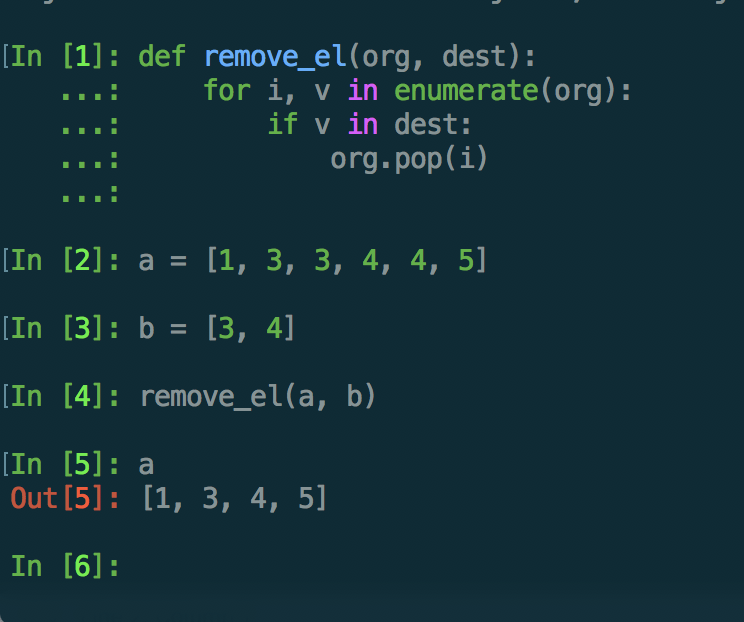
类似的,在循环语句中去修改一个字典,也是不安全的。举个实际例子。
In [1]: a = {'a':0}
In [2]: for k in a:
...: a['0.'+k] = a.pop(k)
...:
In [3]: a
Out[3]: {'0.a': 0}
In [4]: a = {'a':0}
In [5]: for k in a:
...: a['0'+k] = a.pop(k)
...:
In [6]: a
Out[6]: {'00a': 0}
为什么同样的逻辑,上面代码片断居然有两种不同的输出结果?
要理解python的这种行为,得从它的dict类型内部实现说起。
python的字典采用哈希表实现,在初始化字典a的时候,会给它分配一个初始化长度为8的数组,接着给a设置值的时候,通过hash算法算出key的一个整数值,再通过运算将其映射到对应数组中的一个位置,在这个位置上放入对应的值。
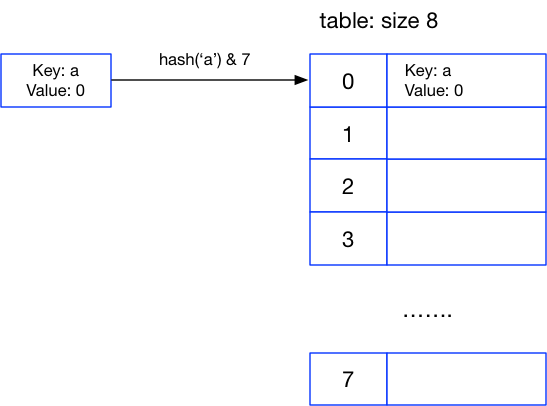
例如我们执行 a = {‘a’:0} 的时候,会计算 a 这个key的hash值对应的数组索引
>> hash('a') & 7
0
这样a元素对应的值就被放到字典中的第一个位置了,这时的字典大概是这个样子的:
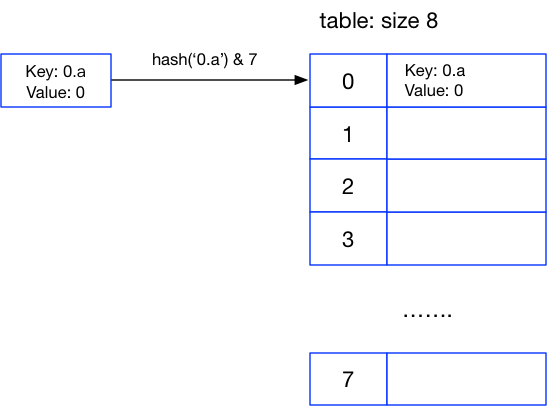
在执行上面第一个for循环时,注意 for k in a 这种语法返回的是一个迭代器,迭代指针最开始指向数组中第一个位置,然后将其 pop 出来,这时字典为空了,再计算 0.a 在数组中的位置:
>> hash('0.a') & 7
0
计算出来的还是位置0,而这个时候位置0的原本值已经被语句 a.pop(k) 给删除掉了,所以可以直接设置值,完成后字典成为这样:
再接着 for 循环接着向数组往后移,但由于字典内数组后面的值全为空,所以for也就不起作用了,最后直接退出,完成后a字典就剩上面这个图这样的了,只有一个元素。
与第一个for循环不一样的是,后面第二次 for k in a 执行的时候,设置的键为 0a ,计算出来在数组中的位置是 3,也就是第4个位置
>> hash('0a') & 7
3
这样的话,这个for循环执行完第一次后,变成了这个样子:
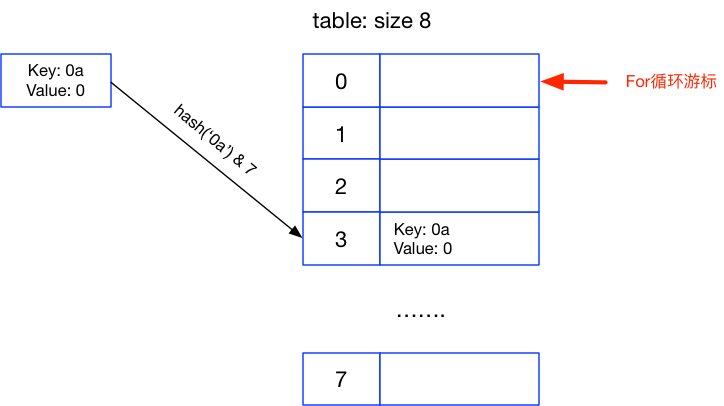
接着for循环的游标继续向下走,遇到了我们刚设置过的值 0a,再执行 a.pop(k),把 0a删除,并计算 00a 的位置:
>> hash('00a') & 7
2
接着便在第3个位置上设置新的值,这时字典长这个样子了:
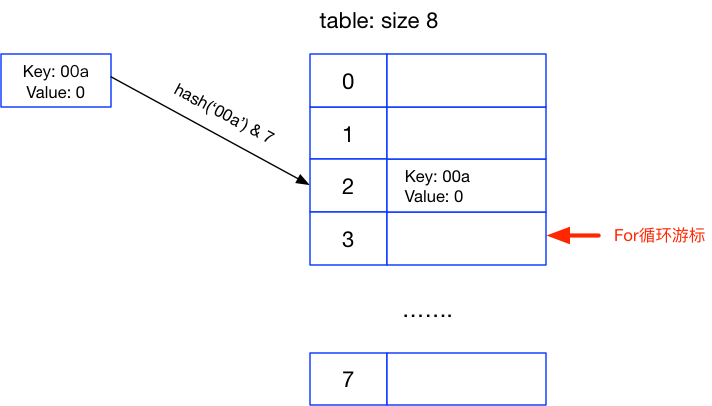
然后for循环接着往下执行,剩下字典的数组没有值了,所以for退出,完成后字典的值就是上面的这样子。
所以理解这个问题的核心主要有两点:
- for语法返回的是一个迭代对象
- 字典设置键值时,根据的hash值来计算对应位置。
如果改成 for k in a.keys() ,就比较安全,不会出现两次执行不一致的问题。