本文主要介绍matplotlib库中pyplot模块的运用,以及更为美观的seaborn库。和一些例子的展示。
数据可视化是当下一个探索、展示结果的有力工具,对于公司而言,做好数据可视化能够更好地对客户介绍自身服务,也能更好地向顾客展示信息。
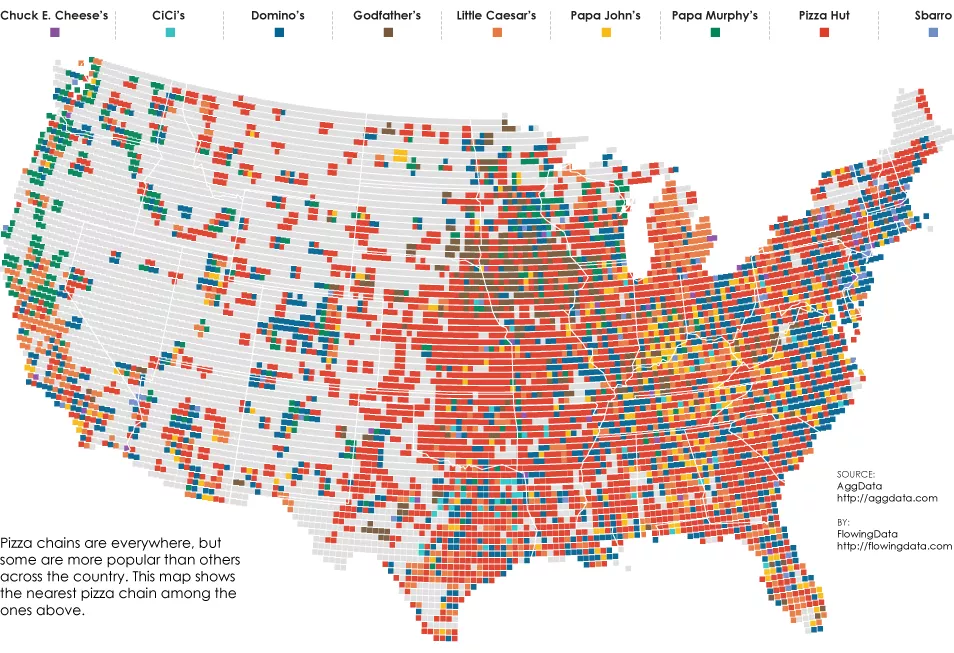
下图是一个咨询公司做的一张美国pizza快餐店的分布图,从图中我们能较为直观的看出不同快餐店在美国不同地区的密度和分布情况,更为重要的是——它吸引眼球。
matplotlib
首先介绍的是Python中最常用也最基础的用于画图的库——Matplotlib,这是一个python的图形框架,能够帮助我们实现一些图形的绘制,我们主要用到其中的pyplot模块。
这个模块可以实现许多基础图表的绘制,可定制参数较多(详见文档),但使用也较复杂,本文只针对图形的展示,对pyplot样式的定制暂不涉及,或由之后的seaborn库更好的实现。
安装:pip install matplotlib
使用: import matplotlib.pyplot as plt
折线图&散点图
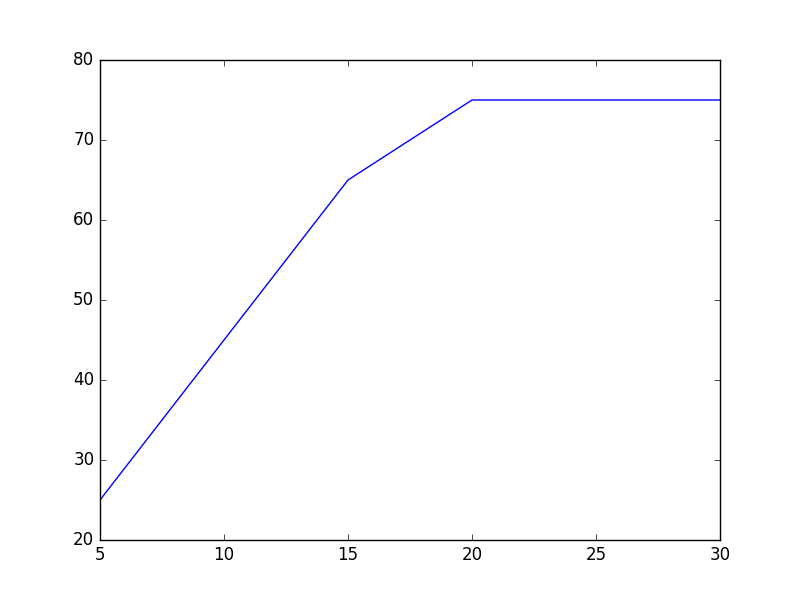
折线图:plot()函数
age = [5, 10, 15, 20, 25, 30] height = [25, 45, 65, 75, 75, 75] plt.plot(age, height) # 以age为横轴,height为纵轴画出折线图 plt.show()
散点图:scatter()函数
weight = [600,150,200,300,200,100,125,180] height = [60,65,73,70,65,58,66,67] # 以weight为横轴,height为纵轴画出折线图 plt.scatter(height, weight)

条形图
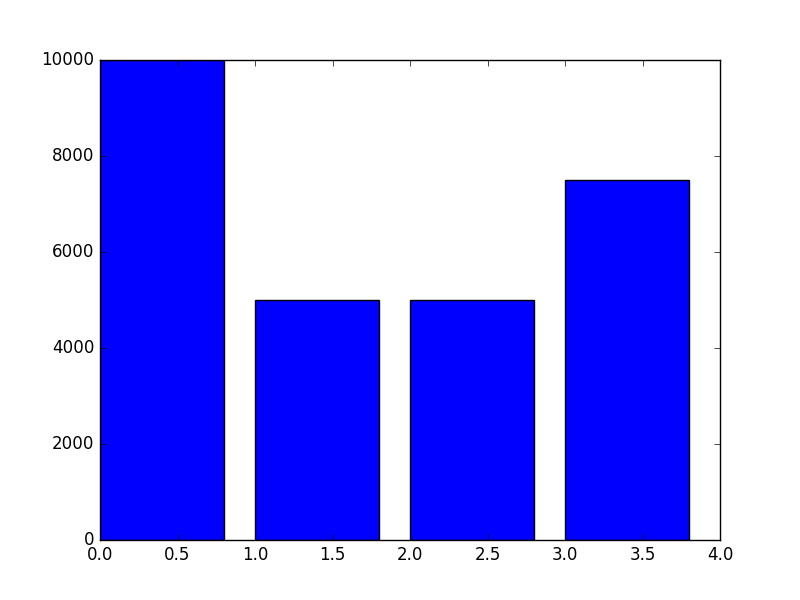
条形图:plt.bar(x, y) , plt.hbar(x, y)
由于matplotlib库的特性,bar()函数的第一个参数只能是数字构成的列表,而不能是string。从而在下图的绘制中,我们引入了x变量。
names = ["McDonalds", "Burger King", "Wendys", "Subway"] patrons = [10000, 5000, 5000, 7500] x = [0, 1, 2, 3] plt.bar(x, patrons) plt.show()
plt.hbar(x, patrons) # horizontal

图注
为了更好地展示信息,我们可以给图标加一些标签:
– 标题:title()方法
– x, y轴标签: xlabel(), ylabel()方法
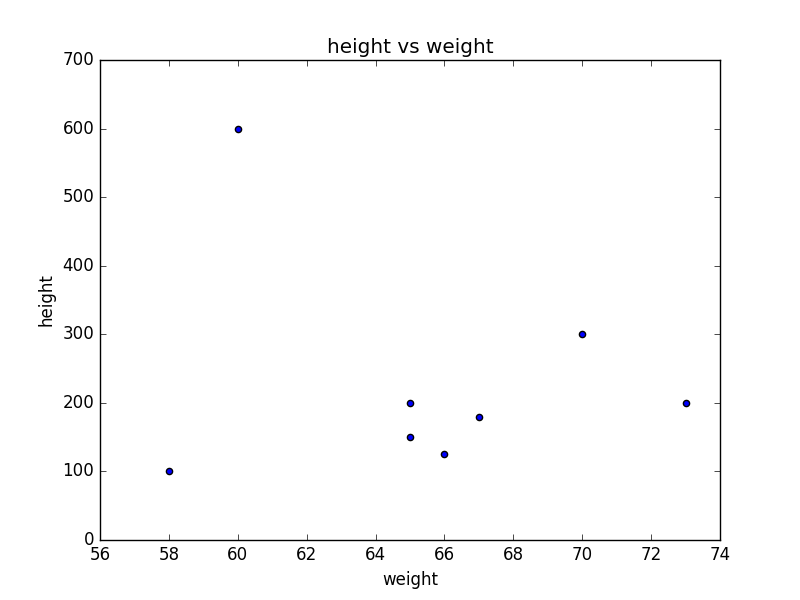
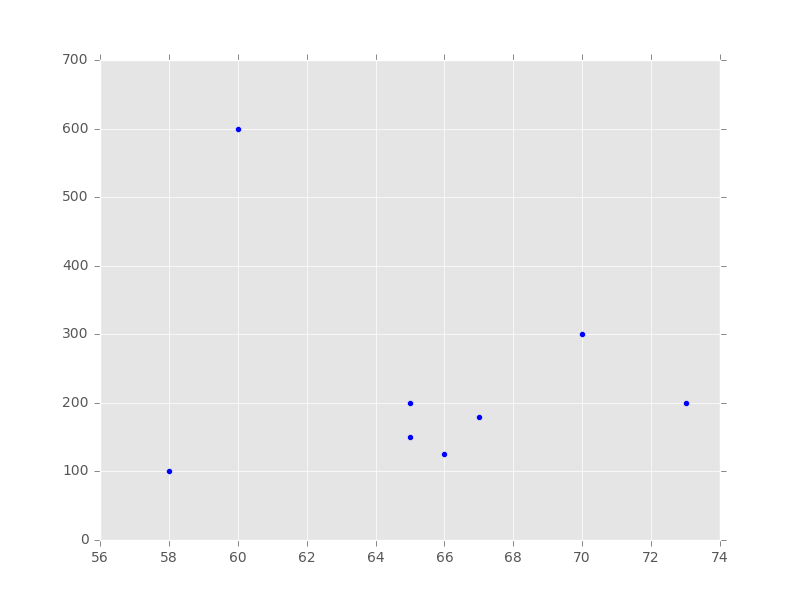
weight = [600,150,200,300,200,100,125,180]
height = [60,65,73,70,65,58,66,67] # 以weight为横轴,height为纵轴画出折线图
plt.scatter(height, weight)
plt.xlabel('weight')
plt.ylabel('height')
plt.title("height vs weight")
图表样式
通过style.use() 函数,我们能够对图表的样式进行定制。Matplotlib库有一些内置的样式供我们使用:
- ggplot: R语言中最流行的绘图库的样式
- bmh: 统计学书籍中常用的样啊是
- dark_background: 为图表提供一个更暗的背景
例子:
weight = [600, 150, 200, 300, 200, 100, 125, 180]
height = [60, 65, 73, 70, 65, 58, 66, 67]
plt.scatter(height, weight)
plt.style.use("ggplot")
实例
本例子将在拥有一个数据集(recent-grads.csv)的基础上,对数据进行导入、基础制图分析的操作。
本例用到的数据可在这里下载。
导入数据
import pandas as pd
recent_grads = pd.read_csv('recent-grads.csv')
print recent_grads.head(3) # 输出导入数据的前三行
Pandas是数据分析中十分常用的一个库,这里仅仅用到它的导入数据功能,数据被导入后将存为DataFrame格式,这是pandas中一种类表格、非常易于操作的数据格式。如下图所示(以上代码的输出):

每一列代表一个专业,以及这个专业的人数、就业率、工资水平等信息
绘制直方图
直方图:DataFrame.hist()
import matplotlib.pyplot as plt
plt.style.use('ggplot')
columns = ['Median','Sample_size']
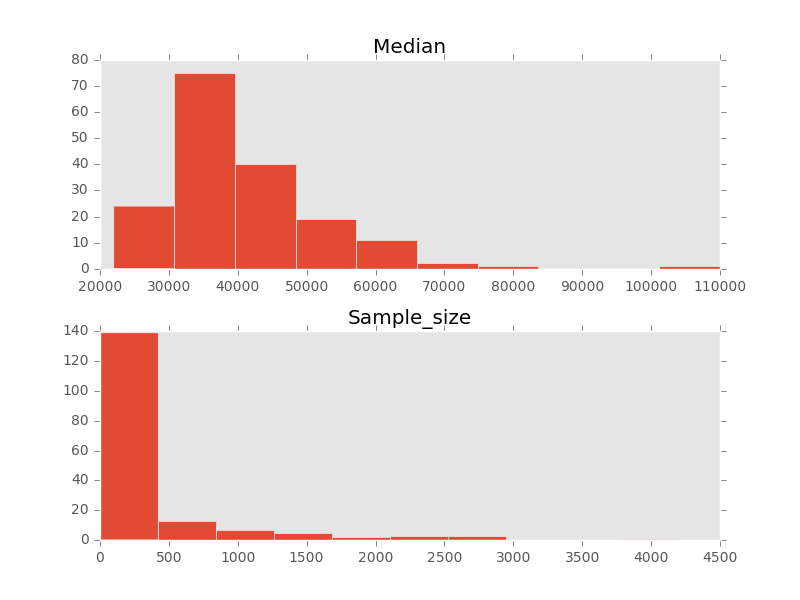
recent_grads.hist(column=columns) #pandas中绘制直方图的方法,参数表示数据源,即针对哪一列

以上是各专业工资中位数和调查样本直方图,但我们发现横坐标的数字由于过于密集导致无法看清,我们可以通过调整图片布局的方式来解决这个问题:
recent_grads.hist(column=columns, layout=(2,1), grid=False)
layout参数表示图片是以2×1的方式排列,grid参数则设定图表中是否有网格。
此时坐标轴的问题解决了,但还有一个问题图表太粗糙了,直方图中每一列覆盖的范围太大了,如果我们想得到更细致的图,可以使用bin参数:
recent_grads.hist(column="Sample_size", bins=50) # 将直方图分成50栏
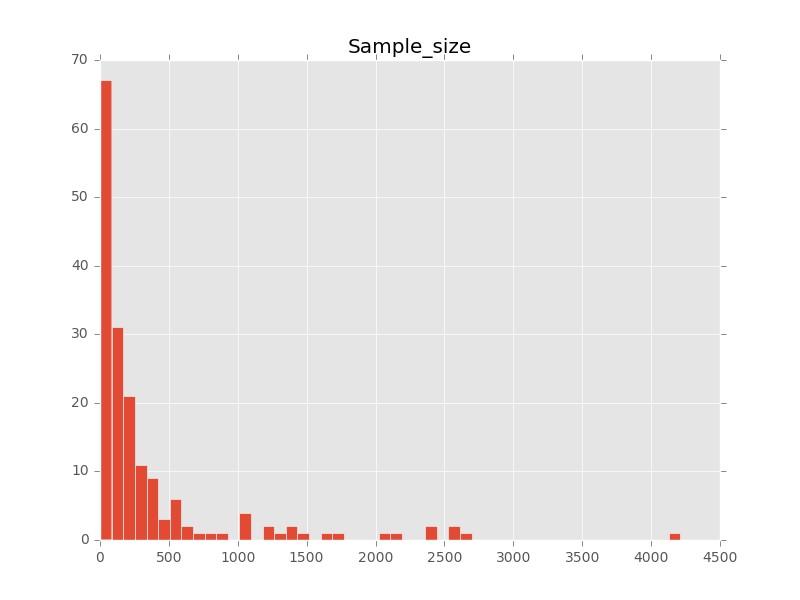
在这个图中我们看到了之前看不到的细节。
通过直方图我们能看出数据的大概分布情况。
箱形图
接下来我们希望研究每个大类(Major_category)中样本的代表性强弱,即通过比较sample_size和Total的箱形图,来看样本中数据的分布和总体的分布是否。
sample_size = recent_grads[['Sample_size', 'Major_category']] # 选择DataFrame中的其中两列,选择的方式和list类似,只是index变成列名 sample_size.boxplot(by='Major_category') plt.xticks(rotation=90) plt.show()
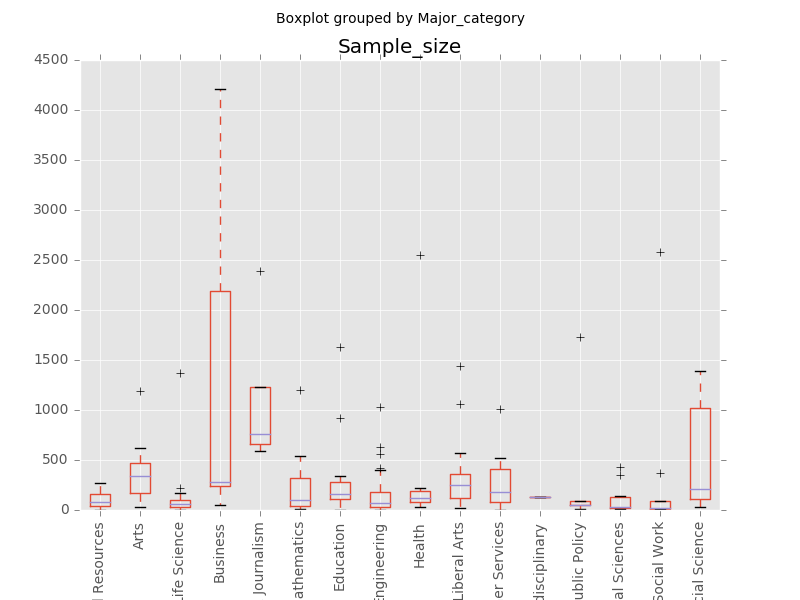
在以上的程序中,Pandas做了以下这些事情:
- 从完整的数据中筛选出Sample_size和Major_category这两栏
- 将Sample_size中的数据按大类分组,每一个Sample_size分到唯一的Major_category,对应代码中的by=’Major_category’
- 对每一个Major_category,用该大类中的Sample_size数据生成箱形图
- 将x轴坐标旋转90度,避免因为间距过窄而造成文字重叠
recent_grads[['Total', 'Major_category']].boxplot(by='Major_category') plt.xticks(rotation=90) plt.show()
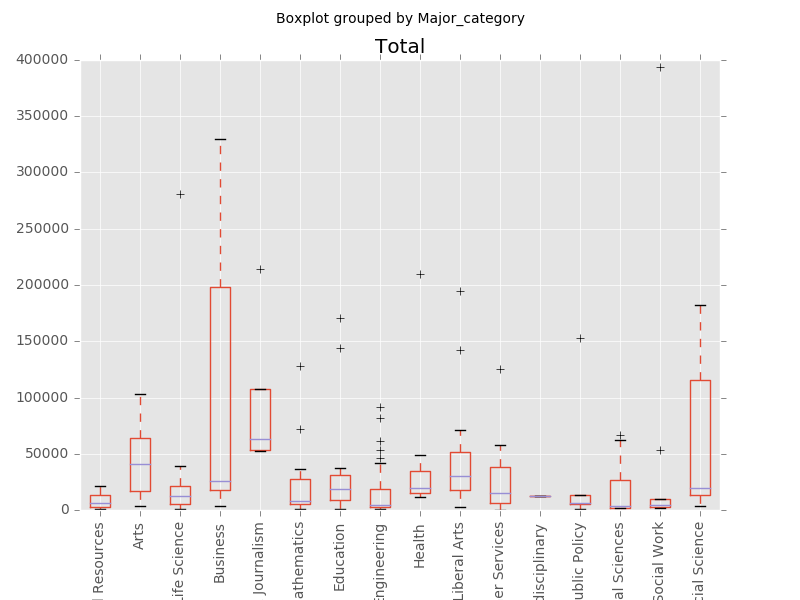
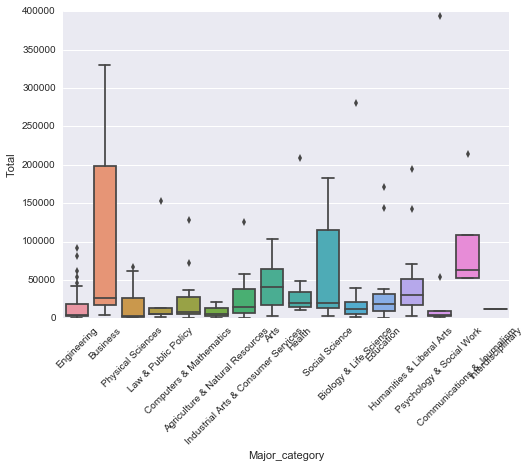
通过比对Sample_size和Total的两张箱形图,我们可以看到样本的分布能够基本反映出总体的分布(即箱形图较为类似),所以我们认为样本的选取是具有代表性的。
将多张图画在一起
这一步我们希望探讨哪些因素能够通过某种方式对毕业生的工资Median有一定的影响,我们将通过散点图来实现:
plt.scatter(recent_grads['Unemployment_rate'], recent_grads['Median'], color='red') # 以Unemployment_rate为x轴,以Median为y轴,画红色的散点图 plt.scatter(recent_grads['ShareWomen'], recent_grads['Median'], color='blue') plt.show()
画的两张图有同样的Y轴,不同的X轴,我们在最后应用plt.show()函数,能够把他们显示在一张图上,更好地进行对比。
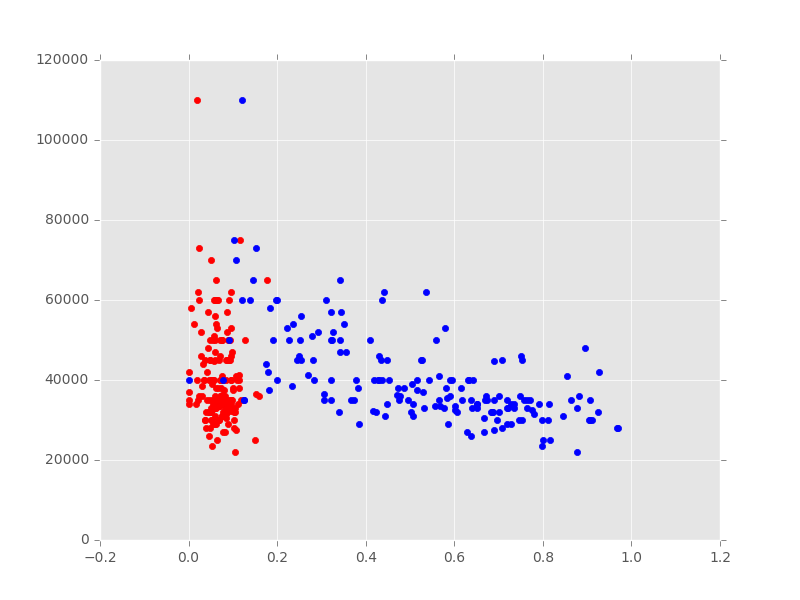
通过上图可以看出,失业率和工资间几乎没有相关性,而女性员工率和工资中位数则存在微弱的线性相关。
Seaborn
Seaborn是一个由斯坦福大学研发的,用于制作presentation级别美观度的数据可视化的包。Seaborn通过matplotlib库的函数来操作数据、定制图表,制作同样样式的图表,Seaborn所需的代码要大大减少、也简单许多。
以下是一些图例的展示:
更多例子详见Gallery。
依赖的库
要顺利使用Seaborn库,须先安装numpy、pandas、matplotlib和scipy(安装Seaborn时会自动安装)库。
Seaborn实例
接下来,我们将用Seaborn绘制一些之前展示过的图表,借此看看其中的差别,说明将放在代码的注释中。
直方图
import seaborn as sns
recent_grads = pd.read_csv('recent-grads.csv')
sns.distplot(recent_grads['Median'], kde=True) # 跟之前介绍的hist()函数功能相同

参数kde=True帮我们画了一条概率密度函数的估计曲线,rug=True使得每一个数据会在图表底部对应的X值处画上一划。除此之外,Seaborn能根据数据的情况自动确定bin值,免去之前调整的烦恼。
箱形图
s = sns.boxplot(recent_grads["Major_category"], recent_grads["Total"])
for item in s.get_xticklabels(): # 获取X轴上的标签
item.set_rotation(45) #将标签旋转45度
Pairplot
data = recent_grads[['Median', 'ShareWomen', 'P25th']] sns.pairplot(data)
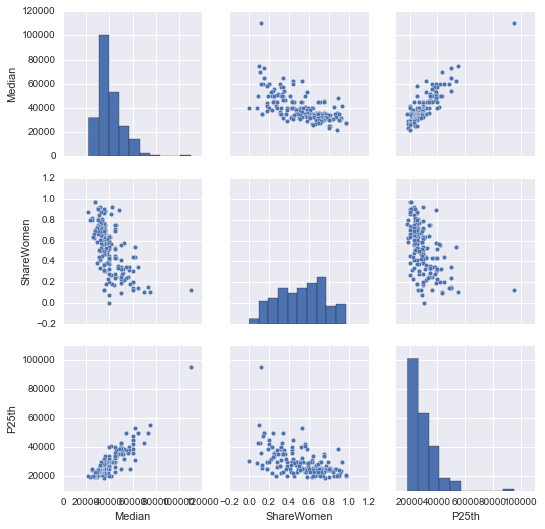
上图的data中我们筛选了三栏,也就是三个变量——工资中位数、女性占比和较小四分数位,其中较小四分位数反映的是该专业工资低收入部分的情况。
在绘制的pairplot中,如果是一个变量对另一个变量(如Median vs ShareWomen)部分,则绘制散点图,如果是同一变量则绘制直方图。
从图中我们可以看出Median和P25th成较强的线性相关,女性占比和工资的中间水平、低收入部分都呈负线性相关。
建议
如果希望开始做数据分析的话,建议直接从Seaborn库开始学习,matplotlib做了解即可。只有当做供自己分析或Seaborn无法完成的图时,可以考虑用matplotlib+Pandas解决。