之前看过一本讲 GPT 原理的电子书《Build a Large Language Model (From Scratch)》 ,感觉还是非常复杂,要求有一些机器学习的基本功才能懂。
然后最近,有大神 Andrej Karpathy 情人节前(2.12)写了篇博客:https://karpathy.github.io/2026/02/12/microgpt/ ,分享如何用 200 行 Python 代码从零写一个类 ChatGPT 算法,用于生成人名。
项目叫 MicroGPT,已开源到 Github:https://gist.github.com/karpathy/8627fe009c40f57531cb18360106ce95
最近有好心人用更通俗的语言和图表写了篇解读:https://growingswe.com/blog/microgpt ,发现还是有点难懂,让 AI 重写一遍,去公式,加名词解释。现在终于能看懂部分了。
训练数据:32000 个名字
模型要学什么?
32000 个人名,一行一个:emma、olivia、ava、isabella、sophia…
任务很简单:学会这些名字的统计规律,然后生成新的、听起来像真名字的词。
训练完之后,模型能输出 “kamon”、”karai”、”anna”、”anton” 这样的名字。
它学会了哪些字母容易跟在哪些后面,哪些音节常出现在开头或结尾,一个名字通常多长。
从 ChatGPT 的视角看,你跟它的对话就是一个文档。
你输入提示词,它的回应就是统计意义上的文档续写。
第一步:把文字变成数字
神经网络只认数字,不认字母。
所以得有个转换方式,最简单的做法是这样的:
给每个独特字符分配一个整数。
26 个小写字母得到 0 到 25 的编号,再加一个特殊标记 BOS(Beginning of Sequence,序列开始),编号 26,用来标记名字的起止。
Tokenizer(分词器):把文本转换成数字序列的工具。就像给每个字符发一张身份证,上面写着专属编号。
比如 “emma” 变成:
BOS(26) → e(4) → m(12) → m(12) → a(0) → BOS(26)

这些整数本身没有大小关系。
4 不比 2 “更大”,它们只是不同的符号,就像给每个字母涂上不同颜色。
生产环境的 Tokenizer(比如 GPT-4 用的 tiktoken)会按字符块切分,词汇表有 10 万个 Token,但原理一样。
预测游戏:猜下一个字
核心任务来了:给定目前看到的 Token,预测下一个是什么。
我们一个位置一个位置往前滑。
在位置 0,模型只看到 BOS,要预测第一个字母。
在位置 1,它看到 BOS 和第一个字母,要预测第二个字母。以此类推。

对于 “emma” 这个名字,会产生 5 个训练样本:
- 看到 [BOS] → 预测”e”
- 看到 [BOS, e] → 预测”m”
- 看到 [BOS, e, m] → 预测”m”
- 看到 [BOS, e, m, m] → 预测”a”
- 看到 [BOS, e, m, m, a] → 预测BOS(结束)
这个滑动窗口,就是所有语言模型的训练方式,ChatGPT 也一样。
从分数到概率:让模型给出确定答案
每个位置,模型输出 27 个原始分数,对应 27 个可能的下一个 Token。
这些分数可以是任何值:正的、负的、大的、小的。
Logits(原始分数):模型最初输出的未经处理的数字,就像考试的原始卷面分,还没有转换成等级。
我们需要把它们转成概率:正数,加起来等于 1,Softmax 就干这个事。
你可以这样理解:假设模型给 5 个候选字母打分是 [1.2, 2.8, 0.5, 1.8, -0.3]。
Softmax 做两件事:
- 把每个分数变成正数(通过指数运算)
- 让它们加起来等于 100%
结果就是一个概率分布,比如 “e” 有 60% 的可能,”a” 有 22% 的可能。
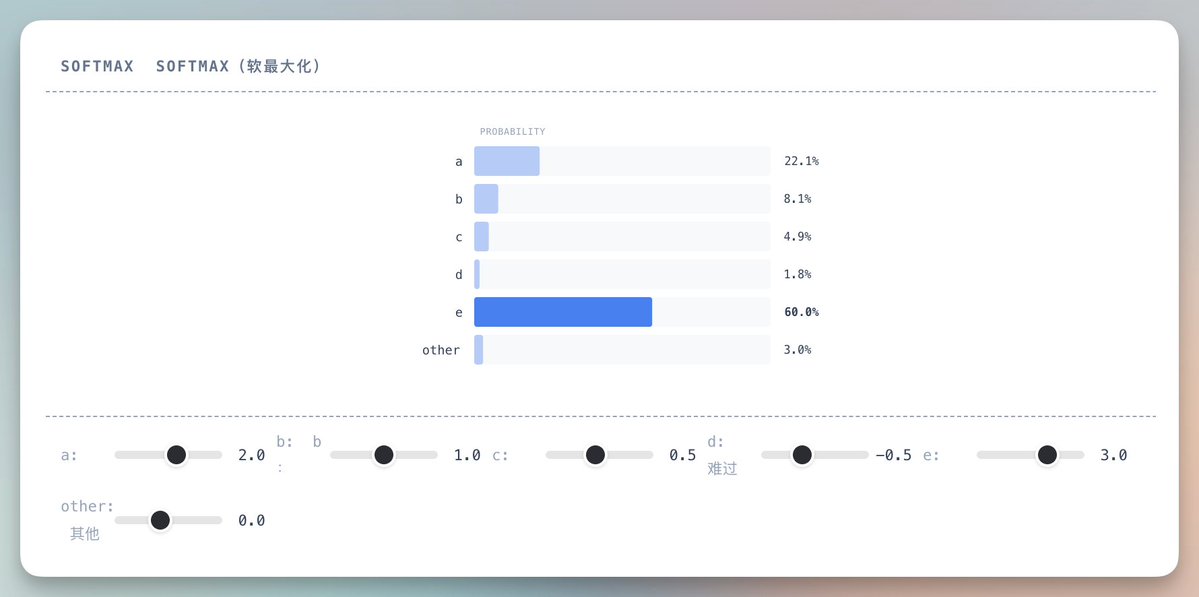
Softmax:把任意数字转换成概率分布的函数。就像把考试分数转换成排名百分比。
注意一个大的分数会主导整个分布,因为指数运算会放大差异。
这也是为什么模型能”确信”某个答案。
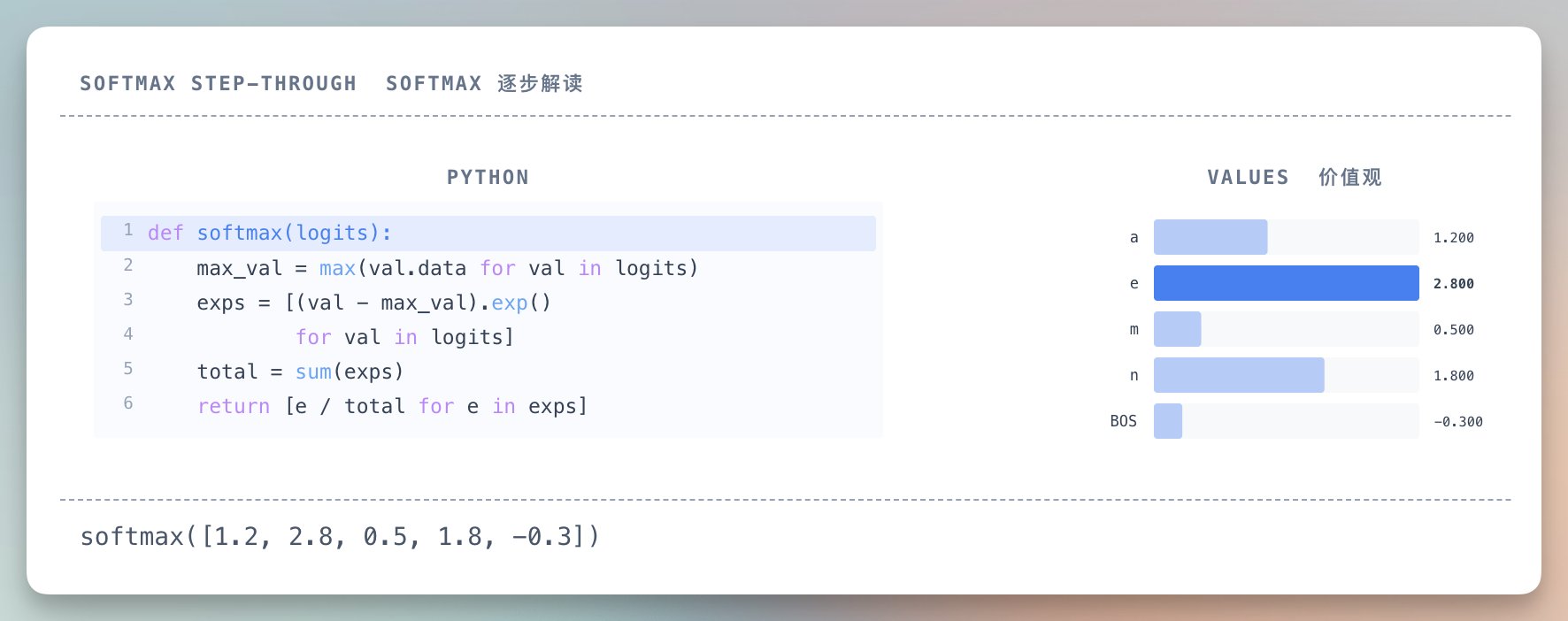
代码里有个小技巧:先减去最大值再做指数。
数学上结果一样,但能防止计算溢出。
衡量错误:模型猜得有多离谱
预测有多离谱?
我们需要一个数字来表示”模型觉得正确答案有多不可能”。
交叉熵损失(Cross-Entropy Loss):衡量预测和真实答案之间差距的指标。模型越确信错误答案,惩罚越重。
举个例子:
- 如果模型给正确答案 90% 的概率,损失很小(0.1)
- 如果只给 1% 的概率,损失很大(4.6)
- 如果完全确信正确答案(100%),损失是 0
模型不仅要答对,还要”有信心地答对”。
如果它给正确答案只分配了很小的概率,即使蒙对了,损失也会很大。
训练就是让这个数字不断变小。
反向传播:找到问题出在哪
模型有 4192 个参数(可以理解为 4192 个旋钮)。
要改进,需要知道:每个旋钮往上调一点点,损失会上升还是下降?
反向传播(Backpropagation):倒着追踪计算过程,找出每个参数对最终错误的贡献。就像出了事故,倒推每个环节的责任。
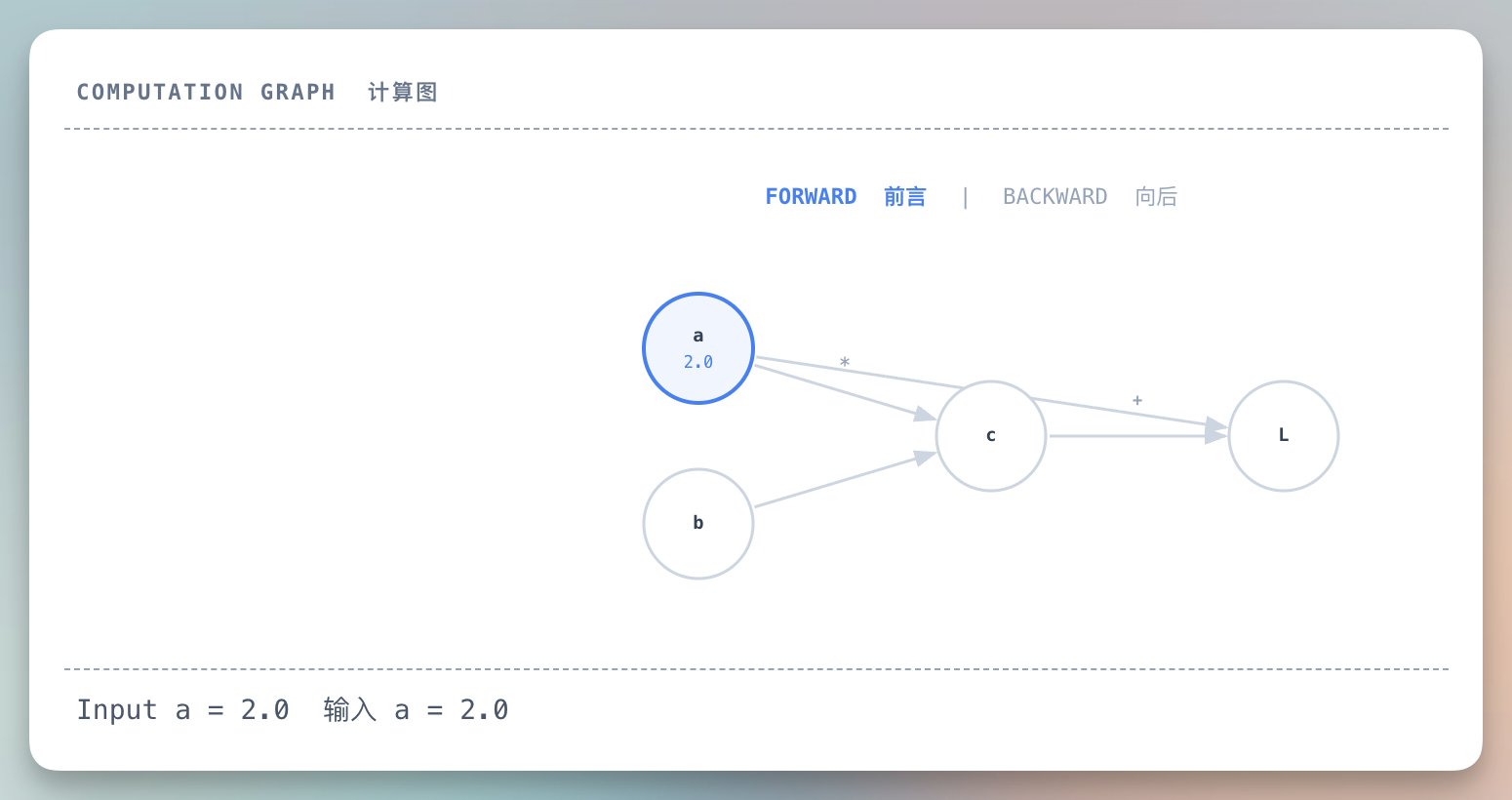
想象一下多米诺骨牌。
前向计算是推倒第一张牌,一路传导到最后。
反向传播是从最后一张倒推回去,看每张牌对最终结果的影响有多大。
每个数学操作(加、乘、指数、对数)记住自己的输入。
反向传播从损失开始,沿着计算路径往回走,给每个参数算出一个”责任分数”。
梯度(Gradient):告诉你参数该往哪个方向调整,以及调整的力度。就像指南针,指向”让错误变小”的方向。
举个例子,假设参数 a 在两个地方被用到。
那它的总责任是两条路径的责任之和。
这就是为什么有些参数的梯度特别大,它们在多个地方影响了最终结果。
PyTorch 的 loss.backward() 跑的就是这个算法,只不过操作的是大批量数据而不是单个数字。
从 ID 到意义:给每个字符一个性格
原始 Token ID(比如 4)只是个索引,模型没法直接用整数做数学运算。
所以每个 Token 会对应一个 16 个数字的列表。
可以理解为每个 Token 有个 16 维的”性格档案”,训练时可以调整。
嵌入(Embedding):把离散的符号(比如字符)转换成连续的数字向量。就像给每个人建立一份多维度的性格档案。
位置也重要,位置 0 的 “a” 和位置 4 的 “a” 作用不同,所以有第二份档案,按位置索引。
两份档案相加,形成输入到网络的向量。

这些数字一开始是随机的小数,训练过程中,模型会自己调整。
训练后,行为相似的 Token(比如元音字母)往往有相似的向量。
模型从零学习这些表示,不需要预先知道什么是元音。
就像小孩学说话,没人告诉他元音和辅音的区别,但他自己能总结出规律。
Token 之间怎么交流:注意力机制
这是 Transformer 的核心。
每个位置需要从之前的位置收集信息。
想象你在读一个句子,读到”她”的时候,你会回头看看前面提到的女性角色是谁,这就是注意力在做的事。
注意力机制(Attention):让模型决定在处理当前位置时,应该重点关注之前哪些位置的信息。就像你读书时,视线会在不同词语之间跳转。
每个token产生三个东西:
- Query(”我在找什么?”)
- Key(”我包含什么?”)
- Value(”如果被选中,我提供什么信息?”)
你可以这样理解:Query 是搜索关键词,Key 是每个位置的标签,Value 是实际内容。
模型用 Query 去匹配所有之前位置的 Key,找到最相关的,然后把对应的 Value 拿过来。
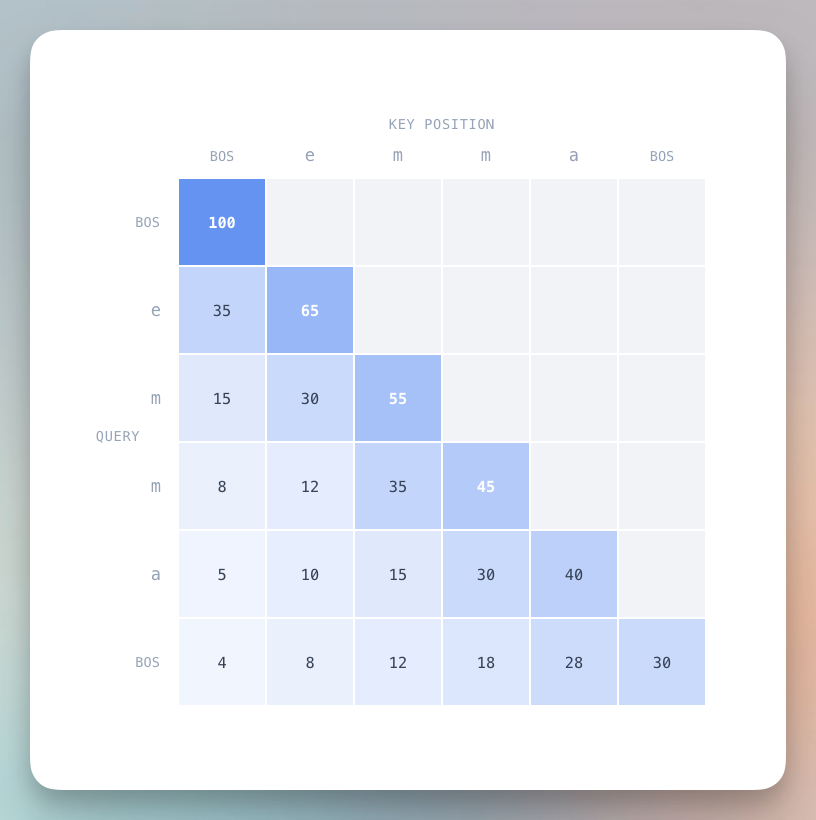
有个重要限制:每个位置只能看过去,不能看未来。
位置 2 不能关注位置 4,因为位置 4 还没发生。
这让模型成为自回归的,符合我们生成文本的方式。
多头注意力(Multi-Head Attention):同时运行多个注意力机制,每个关注不同的模式。就像同时用多个视角看同一个问题。
不同的注意力头学习不同模式:
- 一个头可能强烈关注最近的 Token
- 另一个可能聚焦开头的 BOS Token(记住”我们在生成名字”)
- 第三个可能寻找元音
四个头并行工作,最后把结果拼起来。
完整流程:信息怎么在模型里流动
把每个 Token 想象成一个包裹,在流水线上经过多个工序:
- 嵌入:给包裹贴上标签(Token 性格 + 位置信息)
- 归一化:把包裹整理成标准大小
- 注意力:包裹之间互相交换信息
- 加残差:保留原始包裹的一部分
- 归一化:再次整理
- MLP:每个包裹独立加工
- 加残差:再次保留原始信息
- 输出:得到 27 个分数,对应下一个可能的字符

MLP(多层感知机):一个简单的神经网络,负责对每个位置的信息做独立处理。如果说注意力是”交流”,MLP就是”独立思考”。
残差连接(Residual Connection):在处理信息时保留原始输入的一部分。就像做菜时保留一些原材料的原味,不要全部加工掉。
残差连接特别关键,想象信息在网络里传递就像打电话,每传一层就会损失一些。
残差连接相当于给信息开了一条高速通道,直接跳过某些层,保证重要信息不会丢失。
没有它,深度网络根本训练不起来。
RMSNorm(均方根归一化):把每个向量缩放到标准大小。就像把不同大小的照片统一调整成同样尺寸,方便处理。
学习过程:模型怎么变聪明
训练循环重复 1000 次,每次做这些事:
- 随机挑一个名字
- 把它变成数字序列
- 在每个位置运行模型,预测下一个字符
- 计算预测有多离谱(损失)
- 反向传播,找出每个参数的责任
- 调整参数,让下次预测更准
Adam优化器:一个聪明的参数更新策略。它会记住每个参数最近的表现,对稳定的参数走大步,对摇摆不定的参数走小步。
损失从约 3.3 开始(完全随机猜,27 个选项中瞎蒙),慢慢降到 2.37 左右。
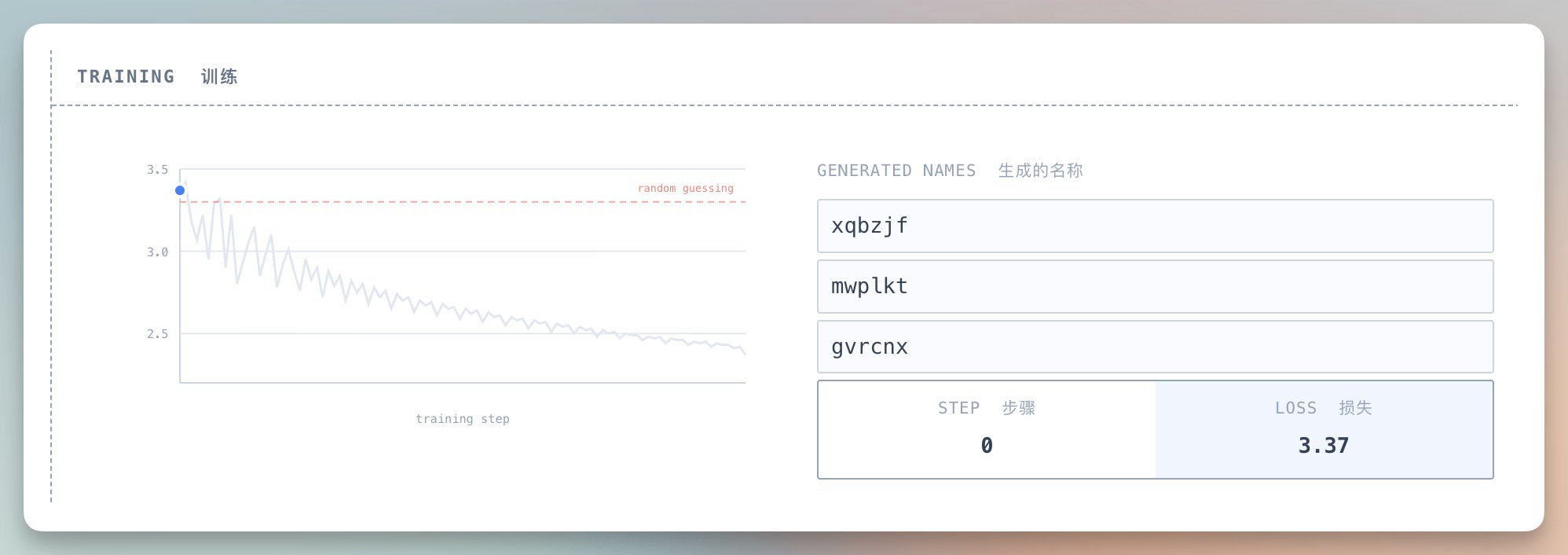
生成的名字也从乱码演变成合理的:
- 刚开始:xqbzjfmwplk(完全乱码)
- 训练中期:kamon, karai(有点意思了)
- 训练后期:anna, anton(完全像真名字)
你能看到模型在”开窍”。
它逐渐理解了什么是合理的字母组合,什么样的音节听起来像名字。
生成新名字:让模型自由发挥
训练完成后,生成很直接:
- 从 BOS 开始
- 让模型预测下一个字符
- 得到 27 个概率
- 随机选一个(按概率)
- 把选中的字符喂回去
- 重复,直到模型说”我完成了”(输出 BOS)
温度(Temperature):控制生成的随机性。低温度让模型更保守(总选最可能的),高温度让模型更大胆(更多尝试不常见的选择)。
你可以这样理解温度:
- 温度 0.5:模型很谨慎,倾向于生成常见的、安全的名字
- 温度 1.0:模型按它学到的真实概率生成
- 温度 2.0:模型很大胆,会尝试不寻常的组合
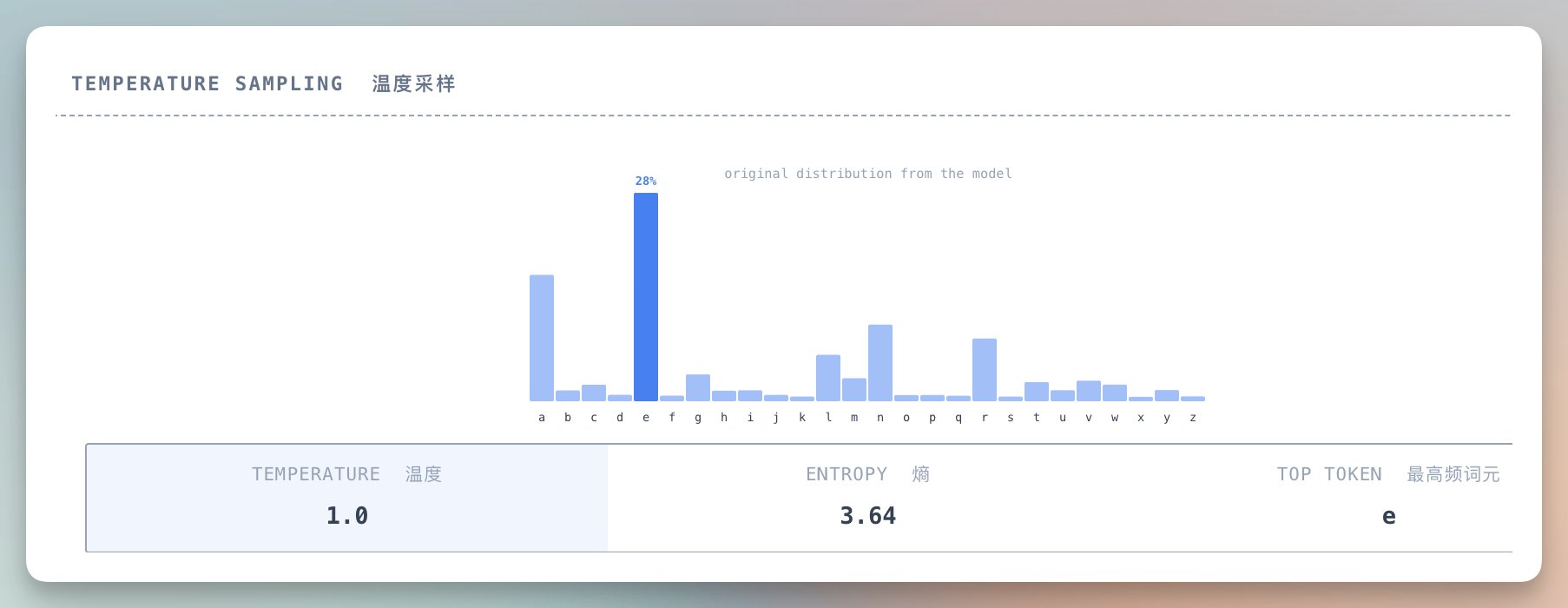
温度太低,生成的东西很无聊,总是那几个最常见的名字。
温度太高,生成的东西可能是胡话。
对于名字,最佳点在 0.5 左右。
既有创意,又不会太离谱。
其他都是效率问题
这个 200 行脚本包含完整算法。
从这个算法到 ChatGPT 的完整实现,核心思想没变。
变的是什么?规模和效率:
- 训练数据:从 32000 个名字到整个互联网的文本
- 词汇表:从 27 个字符到 10 万个子词
- 参数:从 4192 个到数千亿个
- 层数:从 1 层到几百层
- 硬件:从你的笔记本到数千个 GPU 集群
- 训练时间:从几分钟到几个月
但循环是一样的:
分词 → 嵌入 → 注意力 → 计算 → 预测下一个token → 衡量错误 → 反向传播 → 调整参数 → 重复
就这么简单,也就这么复杂。
你现在知道了,ChatGPT 并不神秘。
它就是一个超大规模的”猜下一个词”游戏,玩了无数次之后,变得出奇地聪明。