本来是想研究一下,能不能只读取视频文件的前面很小一部分数据,例如只读开头的 2MB,就可以把内置字幕文件导出来。
结果发现行不通,MP4 和 MKV 文件,它们的字幕都是跟随视频数据一起的,分散到文件的不同位置,所以要导出完整字幕文件,你需要读取整个视频文件。
mp4 文件
MP4 文件是 BOX 模型,这里有个很好的说明文档 https://www.pedestrian.com.cn/user/video/mp4_muxer.html
我们需要读取的 BOX 嵌套规则如下
moov -> trak -> mdia -> mdhd
-> hdlr
-> minf -> stbl -> stts
-> stsz
-> stco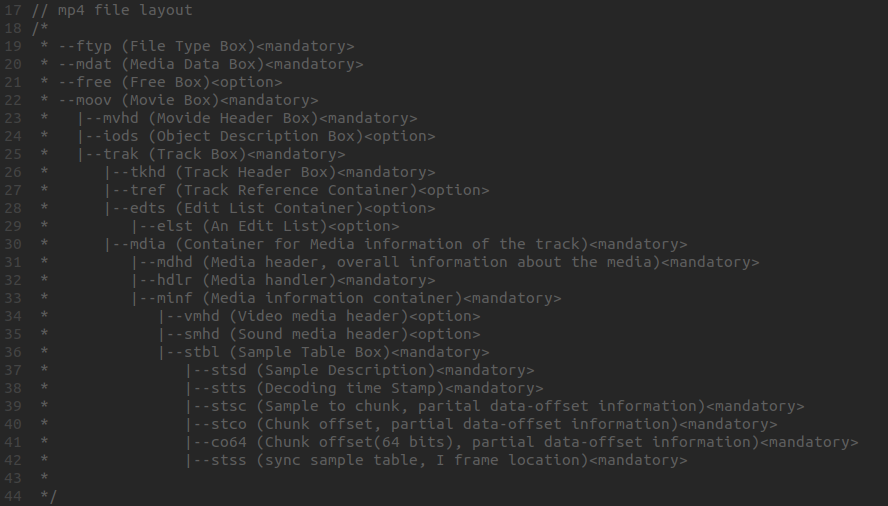
示例程序,读取 mp4 文件,打印出字幕列表,并将其导出为 srt 字幕文件
package main
import (
"encoding/binary"
"fmt"
"io"
"os"
"time"
"github.com/abema/go-mp4"
)
func locateMoov(rs io.ReadSeeker) {
for {
// 获取当前位置
currentPos, _ := rs.Seek(0, io.SeekCurrent)
// 读取 Box Header (8 字节)
var header [8]byte
if _, err := rs.Read(header[:]); err != nil {
break // 到达文件末尾
}
size := binary.BigEndian.Uint32(header[0:4])
boxType := string(header[4:8])
if boxType == "moov" {
fmt.Printf("找到 moov! 起始偏移量: %d,大小:%d\n", currentPos, size)
rs.Seek(currentPos, io.SeekStart) // 回到起点开始详细解析
return
}
if boxType == "mdat" {
var actualSize int64
if size == 1 {
// 处理 64 位大文件长度
var largeSize [8]byte
rs.Read(largeSize[:])
actualSize = int64(binary.BigEndian.Uint64(largeSize[:]))
} else {
actualSize = int64(size)
}
fmt.Printf("跳过 mdat, 大小: %d 字节,当前 offset %d\n", actualSize, currentPos)
// 核心操作:精准跳过 mdat 的主体
rs.Seek(currentPos+actualSize, io.SeekStart)
continue
}
// 其他 Box (如 ftyp, free),根据其 size 正常跳过
rs.Seek(currentPos+int64(size), io.SeekStart)
}
}
// 辅助函数:将 MP4 内部的 uint16 语言代码转为字符串 (如 "chi", "eng")
func decodeLanguage(lang uint16) string {
// 算法:每个字符占 5 位,偏移量为 0x60
c1 := rune((lang>>10)&0x1F) + 0x60
c2 := rune((lang>>5)&0x1F) + 0x60
c3 := rune(lang&0x1F) + 0x60
return string([]rune{c1, c2, c3})
}
type SampleInfo struct {
Offset int64
Size uint32
Start time.Duration
End time.Duration
}
type SubtitleTrack struct {
ID uint32
Language string
Timescale uint32
Samples []SampleInfo
IsSubtitle bool
}
func main() {
if len(os.Args) < 2 {
panic("请提供文件路径")
}
filePath := os.Args[1]
f, err := os.Open(filePath) // 替换为你的文件
if err != nil {
panic(err)
}
defer f.Close()
// 跳过其它 box,直接读取 moov 结构
locateMoov(f)
var tracks []*SubtitleTrack
var cur *SubtitleTrack
// 1. 解析结构
_, err = mp4.ReadBoxStructure(f, func(h *mp4.ReadHandle) (any, error) {
switch h.BoxInfo.Type.String() {
case "moov", "mdia", "minf", "stbl":
return h.Expand()
case "trak":
// 进入新轨道,初始化临时对象
cur = &SubtitleTrack{ID: uint32(len(tracks) + 1)}
_, err := h.Expand()
if cur.IsSubtitle {
tracks = append(tracks, cur)
}
return nil, err
case "hdlr":
payload, _, _ := h.ReadPayload()
hdlr := payload.(*mp4.Hdlr)
if hdlr.HandlerType == [4]byte{'s', 'b', 't', 'l'} {
cur.IsSubtitle = true
}
case "mdhd":
payload, _, _ := h.ReadPayload()
mdhd := payload.(*mp4.Mdhd)
cur.Timescale = mdhd.Timescale
langCode := uint16(mdhd.Language[0])<<10 | uint16(mdhd.Language[1])<<5 | uint16(mdhd.Language[2])
cur.Language = decodeLang(langCode)
case "stts": // 时间表
payload, _, _ := h.ReadPayload()
stts := payload.(*mp4.Stts)
var runningTime uint64
for _, entry := range stts.Entries {
for i := uint32(0); i < entry.SampleCount; i++ {
start := time.Duration(runningTime) * time.Second / time.Duration(cur.Timescale)
runningTime += uint64(entry.SampleDelta)
end := time.Duration(runningTime) * time.Second / time.Duration(cur.Timescale)
cur.Samples = append(cur.Samples, SampleInfo{Start: start, End: end})
}
}
case "stsz": // 大小表
payload, _, _ := h.ReadPayload()
stsz := payload.(*mp4.Stsz)
for i := 0; i < len(cur.Samples) && i < len(stsz.EntrySize); i++ {
cur.Samples[i].Size = stsz.EntrySize[i]
}
case "stco": // 偏移量表
payload, _, _ := h.ReadPayload()
stco := payload.(*mp4.Stco)
for i := 0; i < len(cur.Samples) && i < len(stco.ChunkOffset); i++ {
cur.Samples[i].Offset = int64(stco.ChunkOffset[i])
}
case "co64": // 64位偏移量
payload, _, _ := h.ReadPayload()
co64 := payload.(*mp4.Co64)
for i := 0; i < len(cur.Samples) && i < len(co64.ChunkOffset); i++ {
cur.Samples[i].Offset = int64(co64.ChunkOffset[i])
}
}
return nil, nil
})
// 2. 导出
for _, t := range tracks {
fmt.Printf("%s %d\n", t.Language, len(t.Samples))
saveToSrt(f, t)
}
}
// 解码 MP4 内部语言代码 (ISO-639-2/T)
func decodeLang(l uint16) string {
// 5位一个字母,偏移量 0x60
c1 := byte((l>>10)&0x1F) + 0x60
c2 := byte((l>>5)&0x1F) + 0x60
c3 := byte(l&0x1F) + 0x60
return string([]byte{c1, c2, c3})
}
func saveToSrt(f io.ReadSeeker, t *SubtitleTrack) {
outName := fmt.Sprintf("track_%d_%s.srt", t.ID, t.Language)
out, _ := os.Create(outName)
defer out.Close()
fmt.Printf("导出轨道 %d [%s], 共 %d 条字幕...\n", t.ID, t.Language, len(t.Samples))
for i, s := range t.Samples {
f.Seek(s.Offset, io.SeekStart)
data := make([]byte, s.Size)
f.Read(data)
if len(data) < 2 {
continue
}
txtLen := binary.BigEndian.Uint16(data[:2])
if int(txtLen)+2 > len(data) {
txtLen = uint16(len(data) - 2)
}
content := string(data[2 : 2+txtLen])
fmt.Fprintf(out, "%d\n%s --> %s\n%s\n\n",
i+1, formatSrtTime(s.Start), formatSrtTime(s.End), content)
}
}
func formatSrtTime(d time.Duration) string {
ms := d.Milliseconds() % 1000
sec := int64(d.Seconds()) % 60
min := int64(d.Minutes()) % 60
hr := int64(d.Hours())
return fmt.Sprintf("%02d:%02d:%02d,%03d", hr, min, sec, ms)
}
mkv 文件
示例程序,读取 mkv 文件,打印出字幕列表。这里就没继续研究导出字幕文件了,要读取整个 mkv 文件,比较麻烦,而且速度也较慢。
package main
import (
"fmt"
"io"
"os"
"github.com/at-wat/ebml-go"
)
// SubtitleTrack 存储 MKV 字幕轨道信息
type SubtitleTrack struct {
Number uint64
Language string
Name string
CodecID string
}
func main() {
if len(os.Args) < 2 {
panic("请提供文件路径")
}
filePath := os.Args[1]
f, err := os.Open(filePath)
if err != nil {
panic(err)
}
defer f.Close()
headReader := io.NewSectionReader(f, 0, 100*1024) // 读取前 100k,通常足够包含头部信息
tracks, err := listMKVSubtitles(headReader)
if err != nil {
fmt.Printf("解析列表时出错 (可能是数据不足): %v\n", err)
}
if len(tracks) == 0 {
fmt.Println("未发现内置字幕轨道")
return
}
fmt.Println("--- 发现字幕列表 ---")
for _, t := range tracks {
fmt.Printf("[%d] 语言: %s, 格式: %s, 名称: %s\n", t.Number, t.Language, t.CodecID, t.Name)
}
}
func listMKVSubtitles(r io.ReadSeeker) ([]SubtitleTrack, error) {
r.Seek(0, io.SeekStart)
var header struct {
Segment struct {
Tracks struct {
TrackEntry []struct {
TrackNumber uint64 `ebml:"TrackNumber"`
TrackType uint64 `ebml:"TrackType"`
Language string `ebml:"Language"`
Name string `ebml:"Name"`
CodecID string `ebml:"CodecID"`
} `ebml:"TrackEntry"`
} `ebml:"Tracks"`
} `ebml:"Segment"`
}
// Unmarshal 会尝试解析整个结构,但在读取完 Tracks 后我们就可以停止
// 即使因为文件不完整报错,header 里的信息通常也已经填充了
err := ebml.Unmarshal(r, &header)
var result []SubtitleTrack
for _, t := range header.Segment.Tracks.TrackEntry {
if t.TrackType == 17 { // 17 是 MKV 标准中的 Subtitle 类型
result = append(result, SubtitleTrack{
Number: t.TrackNumber,
Language: t.Language,
Name: t.Name,
CodecID: t.CodecID,
})
}
}
return result, err
}